Part two: continuing an exploration of Large Language Models’ ability to ‘explain’ complex texts.
Posted on Tuesday 7 May 2024

Here are a couple of extracts from the system instructions:
Part 1 failure logic analysis (extract):

Part 2 example code output (extract):

Despite trying dozens of variants and re-tweaks, the basic framework of the system always contained these two elements. It could be that the GPT would have benefited from splitting the task into two parts, or more, but we didn’t have much time to explore this in detail.
So why did FLAGPT not perform as expected?
There were several issues that turned out to be harder to resolve than we thought. The first of these is misalignment (doesn’t do what we ask) or the model is ‘lazy’ (stops the analysis at a superficial level).
The second is simply that it does an incorrect analysis of the system (i.e. it gets the failure logic wrong).
Finally, it wouldn’t follow its system instructions for visualisation (reverts to GPT-4 and produces a full LaTeX environment or something else).
So now let’s look at a typical example of what we’re trying to achieve with FLAGPT. We’re aiming to give it a system description and produce a final outcome that resembles a fault tree:

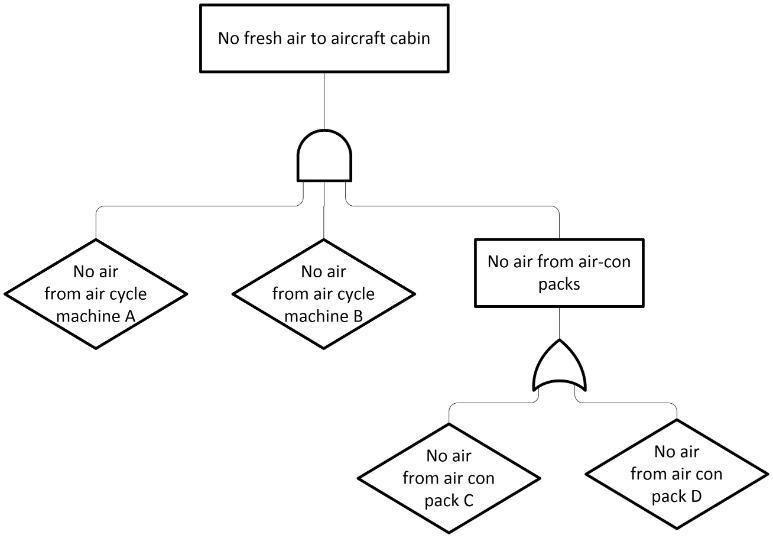
The sections highlighted in yellow indicate redundancy (always modelled using an AND failure logic gate) and the subtle effect wording can have. Note especially the word ‘BOTH’ - this seemed to fool FLAGPT into always thinking this dependency should be modelled by an AND gate, instead the OR gate that is correct as both air con units were needed to maintain air pressure.
First go, and FLAGPT would generally get most of it wrong. But as previously mentioned, you can repeat it many times, each asking FLAGPT to correct its mistakes and eventually you will end up with something close enough to what you want or can use.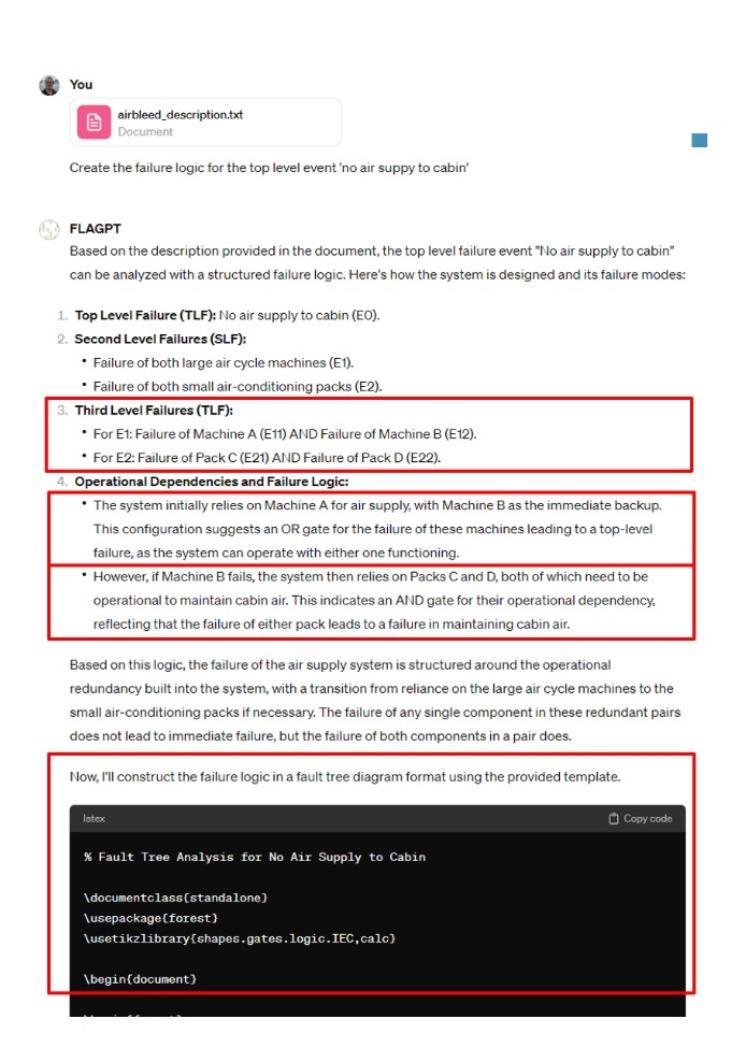
Red boxes show errors in FLAGPT's output.
Although the above answer contains errors in almost every part, with a lot of cajoling, correction, and other forms of repeated instruction, eventually you would be able to get an output to visualise (via Overleaf) to look something like this:
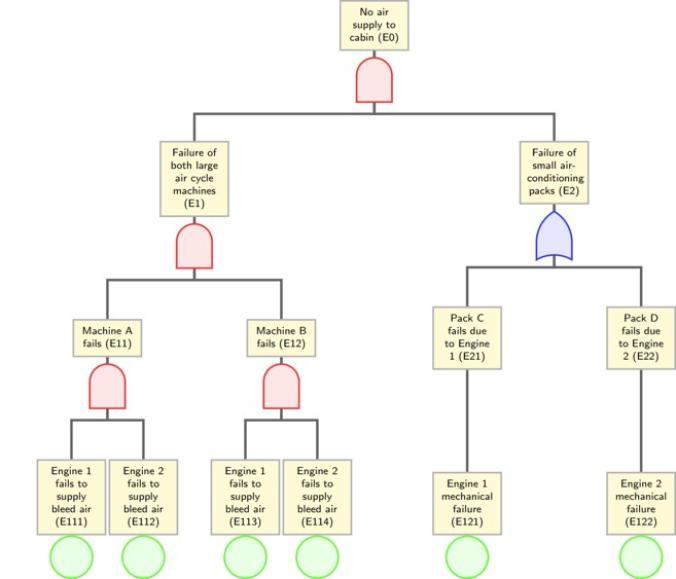
The question is, does this process save time / produce sufficient quality to be useful? This is a more difficult question to answer than you might think, as not all errors are equal when analysing systems for failure logic.
The final blog: Part three: why was FLAGPT making errors and should we blame the underlying mode? will reveal more.