Blog post: Rewards and reprimands: teaching a medical AI to be safer
Posted on Wednesday 10 August 2022

Sepsis (severe infections with organ failures) is a leading cause of death in the UK. Combatting sepsis happens on several fronts: patients are given antibiotics to clear their body from the infectious agent, while support is given to some of their key organ functions if need be; ventilators to support lungs, dialysis machines for failing kidneys, and a variety of drugs to assist the cardiovascular system. The latter remains particularly challenging and, despite decades of research, the haemodynamic management of sepsis remains controversial.
Can we safely use AI to improve sepsis treatment?
In 2018, our Imperial College laboratory published the AI Clinician, a reinforcement learning (RL) agent that successfully learnt optimal treatment strategies for those cardiovascular drugs, namely intravenous fluids (sterile salty water injected into the veins to maintain blood volume) and vasopressors (drug squeezing the blood vessels, mainly arteries to increase the blood pressure).

The key factor that drives an RL agent’s behaviour is reward. RL AI agents are trained to make decisions that will, in the long run, maximise a pre-defined expected future reward.
Want to train an RL agent to master chess? Give it a reward when they win a game! Want to teach an RL agent to drive on a road? Give it a penalty every time they exit the desired path! Want to teach an RL agent to treat a disease? Give it a reward every time a patient has a positive outcome!
This is what we successfully did in our initial publication. Our next step was to assess and refine the safety of this algorithm through a collaboration with the Assuring Autonomy International Programme (AAIP) at the University of York.
A safety perspective on the AI Clinician: can we build a safer system?
Decision support systems in the healthcare environment are complex, with numerous interconnected moving components and multiple stakeholders. As such, assessing their safety is a complex and challenging task which requires the collaboration between domain experts (clinicians), technical experts (AI and computer scientists), and safety and human factors experts.
Our collaboration with the AAIP enabled this multidisciplinary interaction to advance the safety assessment of our AI Clinician system. We wanted to benefit from the insights and expertise of the safety engineering community, and apply their tools to our healthcare application — a very novel approach.
The AAIP developed the Assurance of Machine Learning for use in Autonomous Systems (AMLAS) methodology, a cross-domain safety assessment framework for autonomous applications. In the first part of our AAIP project, we applied AMLAS to the AI Clinician.
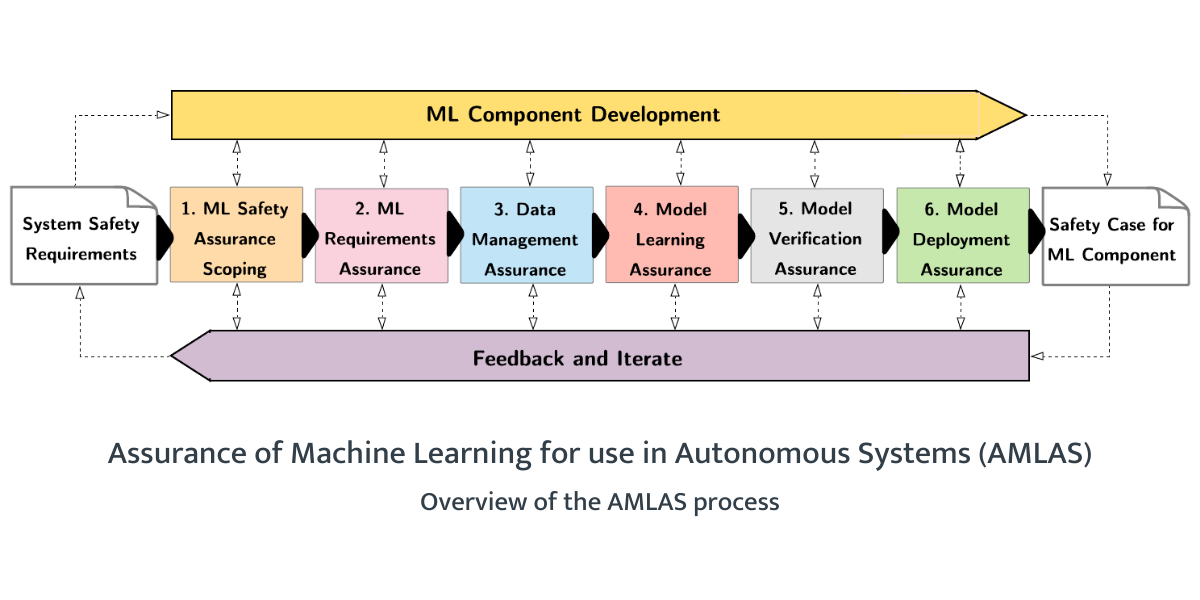
AMLAS considers the total product life cycle of autonomous applications, from safety requirements, data management and model learning to validation and deployment, in an iterative fashion where safety evidence gathered throughout the process can inform the design of future versions of the tool.
When applying AMLAS to the AI Clinician, Dr Yan Jia (AAIP Research Associate) identified as a potential safety hazard the fact that there were no hard encoded rules in the AI agent that would prevent it from taking obviously dangerous decisions.
Using the analogy of self-driving cars, such actions would be equivalent to an autonomous vehicle reversing into a wall, or, at an intersection, advancing into a road jammed with busy traffic without stopping. Avoiding those behaviours does not make the car 100% safe in any situation possible, but it helps improve its overall safety profile.
Coming back to our healthcare setting, the clinicians in our team (including Professor Anthony Gordon and Dr Matthieu Komorowski) identified a set of scenarios and treatment options that would be unquestionably dangerous for the patient. In particular, we focused on underdosing and overdosing fluids or vasopressors to the extreme.

We detailed this approach in a recently accepted peer-reviewed publication. While we don’t necessarily know what the ideal dose of intravenous fluids and vasopressors are for a given patient, it is well recognised that giving further fluids to a patient who is already fluid overloaded is harmful.
Sepsis, especially in its severe forms, leads to a drop in blood pressure which ultimately leads to end-organ damage and death. As such, not treating profound hypotension is also dangerous behaviour. Limiting the ability of an AI agent to make these decisions is likely to improve its safety profile. In the RL realm, we talk about limiting the action space to avoid transitioning into dangerous health states.
As we discussed above, the key determinant of the RL agent’s behaviour is the reward, which drives the AI to do one thing rather than the other. In order to integrate our established unsafe scenarios into the training of the model, we gave the AI agent additional penalties if it suggested underdosing or overdosing vasopressors and/or fluids. Then, we retrained our model and assessed its new safety profile.
The new agent, trained with these new reward signals, demonstrated fewer unsafe recommendations than both human clinicians and the original AI while maintaining great performance (in terms of expected patient survival).
In other words, adding these safety penalties to the natural reward function led the AI to another appropriate, yet safer, treatment strategy.
A look at the future
In this post, we’ve seen how a tight collaboration between safety engineers (at the AAIP) and clinicians and AI scientists (at Imperial College London) has enabled the development of a new methodology to improve the safety profile of RL agents, which will power bedside decision support systems in the near future. These results are reported in a full-length paper recently accepted.
While this demonstrator used the AI Clinician system for sepsis treatment, the approach is flexible enough to be used in any RL-based systems, provided researchers can define undesirable behaviour.
The team is now working on another stage of the AMLAS methodology, namely model deployment and evaluation. Here, we are deploying the tool in a high-fidelity ICU simulation suite, to test how human clinicians interact with the AI, what level of trust can be generated by the system, and what factors influence the trust in the system by human operators.
By doing it in a physically simulated environment, we reproduce most of the factors present in real-life clinical scenarios, without endangering human lives if the AI were to behave unexpectedly or lead to unintended consequences. This step-wise approach to safe AI development and deployment is at the core of the partnership between our two institutions.
---
Paul Festor
PhD candidate
Imperial College London
and Matthieu Komorowski
Clinical Senior Lecturer
Imperial College London
Paul and Matthieu are also researchers on the AAIP-funded project, Safety of the AI clinician.